截音源一直是制作人力VOCALOID时最麻烦的一个步骤,那有没有办法能简化这一步骤呢?
目前最早利用ai自动制作utau音源的尝试应该是来自Chaosinism的utau_tools,详情可以阅读:利用语音识别技术辅助制作音源的初步尝试。
这种方案的流程为:试用IBM Watson的语音转文本api,利用识别出的带时间戳的文本自动分割音频。Watson的弊端在于并非开源免费,而且仅能以词为基本单位给出时间戳,对于识别到的多字词语,只能基于时间平均分割开来。当时我进行了简单修改来支持处理日语数据,最终效果可以参考:Big brother
而后DJGun团队也使用Vosk的开源语音转文本模型开发了自动截音源的脚本,这个脚本应该可以说是目前流传最广的截音源脚本。虽然DJGun的脚本只能以识别到的单个词为单位自动分割音源,但实际上vosk可以直接按逐个单字/假名给出结果,可以参考笔者以前编写的脚本。Vosk的缺点在于,它识别的准确率比较感人,而且在识别日语的时候经常只能零零星星认出几个假名,需要丢进去大量数据才能截出能用的音源。
而到今年,DiffSinger这个SVS库开始支持用非歌唱数据炼丹了,而且仅需标好对应拼音文本,无需按音节精细标注时间即可自动生成标注。(题外话:数据量足的话其实可以直接炼DiffSinger了,效果可以接近真人)其中一个很关键的步骤,就是将语音文件和标注好的拼音文本输入MFA,就能生成对应的TextGrid文件,而TextGrid中的标注甚至能精确到辅音和元音这样的基本单位。(需要注意的是,MFA的精确度与输入文本的精确度密切相关,如果文本是对的,那么标注基本上就会非常精确)
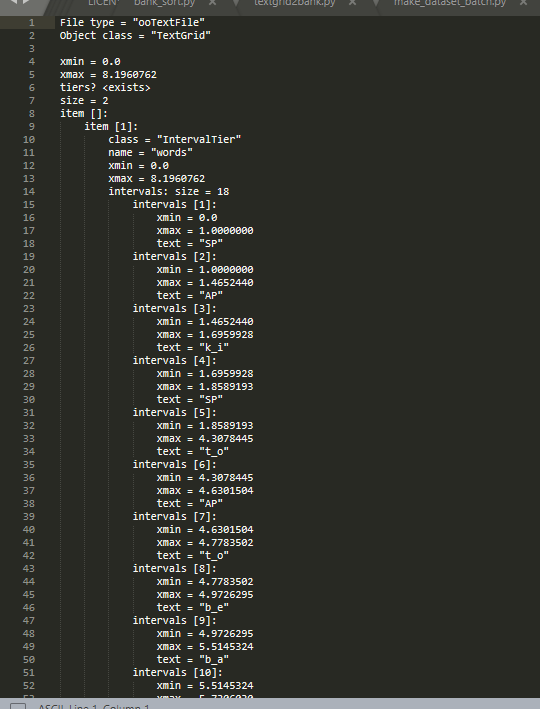
至此,我们得到了一种完全自动的截音源的思路:先用准确率较高的语音转文本模型(如whisper)生成标注文本,然后丢给MFA,最后按TextGrid截出来,以音频时长排序保留效果好的文件。
不过笔者目前并没有打通第一个步骤,毕竟whisper虽然比vosk强,但准确率仍然比较感人。目前笔者已经实现了利用赛马娘游戏提取的文本和语音自动截取音源的脚本,效果可以看这个合作单品,直接大大提高了赶合作的效率。